
If you’ve ever wondered how AI models like Qwen understand and process text, the answer lies in something called a tokenizer.
A tokenizer is like a translator that breaks down text into smaller parts, making it easier for the AI to understand.
But what kind of tokenizer does Qwen use, and why does it matter?
In this article, I will explain to you What Tokenizer Qwen Use. But, first of all, let’s find out what a tokenizer is.
What is a Tokenizer and Why is it Important?
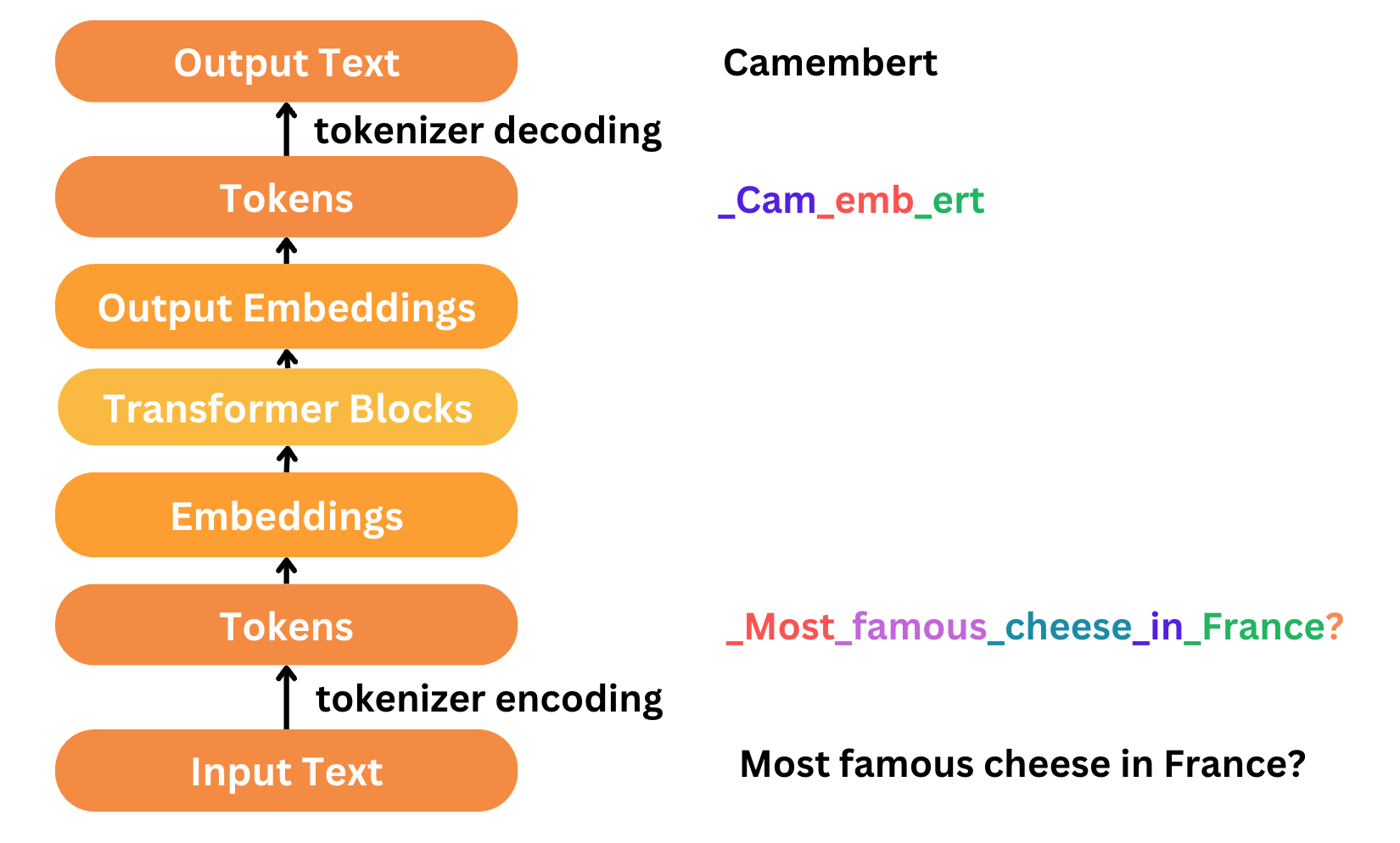
Before we dive into Qwen’s tokenizer, let’s first understand what a tokenizer does.
Imagine you’re trying to teach a child to read.
Instead of showing them long sentences, you start by breaking them into smaller words, then syllables, and finally individual letters.
This step-by-step process makes learning easier.
That’s exactly what a tokenizer does, it breaks text into smaller parts, or tokens, so the AI can process it more efficiently.
Tokenization is a crucial step in natural language processing (NLP) because it helps AI models understand context, grammar, and meaning.
Without a good tokenizer, AI models would struggle to comprehend and generate meaningful responses.
Tokenizer Used by Qwen
Qwen uses a Byte Pair Encoding (BPE) tokenizer applied to UTF-8 text.
This method first breaks down text into bytes and then combines the most frequently used byte pairs to form larger, more meaningful units.
This approach allows Qwen to process text efficiently while keeping the vocabulary size manageable.
Key Features of Qwen’s Tokenizer

-
Byte-Based Tokenization: It starts by treating each byte as an individual token, ensuring that no text is left out.
-
Merges Common Byte Pairs: The tokenizer gradually merges frequently occurring byte sequences to create meaningful subwords.
-
No Missing Words: Since every word can be broken down into bytes, Qwen doesn’t face the issue of unknown words.
-
Works for Multiple Languages: This method ensures that Qwen can handle different languages and scripts with ease.
Special Tokens Used in Qwen’s Tokenizer
A tokenizer doesn’t just break down words, it also includes special symbols, known as special tokens, to help structure conversations.
In Qwen’s tokenizer, some of these tokens include:
-
<|im_start|>– Marks the start of a conversation turn. -
<|im_end|>– Marks the end of a conversation turn. -
<|endoftext|>– Indicates the end of a document or conversation.
These special tokens play a crucial role in making AI-generated responses more natural and structured.
Why Qwen’s Tokenizer is Efficient
Qwen’s BPE tokenizer is designed to be both accurate and flexible. Here’s why it stands out:
-
Reduces Vocabulary Size: Instead of storing full words, it stores commonly used subword units, making processing faster.
-
Improves Understanding of New Words: Since it breaks down words into smaller parts, Qwen can understand even those words it hasn’t seen before.
-
Supports Different Languages: Whether it’s English, Chinese, or another language, this tokenizer ensures that Qwen can handle it efficiently.
Can You Fine Tune Qwen’s Tokenizer?
Yes! If you’re fine-tuning Qwen for a specific application, you may want to adjust the tokenizer.
Here’s how You Can Customize Qwen’s Tokenizer:
-
Handle Special Tokens Properly: Ensure that tokens like
<|im_start|>and<|endoftext|>are placed correctly. -
Expand the Vocabulary if Needed: If you’re working with highly specialized terms, you can add new tokens to improve accuracy.
-
Optimize for Specific Languages: If your use case involves a particular language, tweaking the tokenizer may help improve results.
Conclusion

Qwen’s tokenizer is a crucial part of its ability to process and generate text accurately.
By using Byte Pair Encoding (BPE) and handling text at the byte level, it ensures efficient tokenization across multiple languages.
With over 151,000 tokens, including special control tokens, Qwen’s tokenizer helps structure conversations and improve AI interactions.
Whether you’re using Qwen for chatbots, content creation, or any other NLP task, understanding how its tokenizer works can help you get the best results.
By customizing it for specific needs, you can make Qwen even more powerful for your applications.
Frequently Asked Questions (FAQs)
What is a tokenizer in AI?
A tokenizer is a tool that breaks down text into smaller units, called tokens, which can be words, subwords, or characters. This helps AI models process and understand text more efficiently.
What tokenizer does Qwen use?
Qwen uses a Byte Pair Encoding (BPE) tokenizer applied to UTF-8 text. It starts by breaking text into bytes and then merges frequently used byte pairs to form meaningful subword units.
Why does Qwen use a Byte Pair Encoding (BPE) tokenizer?
BPE is efficient because it reduces vocabulary size, improves text understanding, and works well across multiple languages. It also prevents unknown token issues since every word can be broken down into smaller units.
Can Qwen’s tokenizer handle multiple languages?
Yes! Since it processes text at the byte level and merges frequently used patterns, Qwen’s tokenizer can handle various languages and writing scripts effectively.
What is the vocabulary size of Qwen’s tokenizer?
Qwen’s tokenizer has a vocabulary of over 151,000 tokens, including regular words, subwords, and special control tokens.
How does Qwen’s tokenizer improve AI-generated responses?
By efficiently breaking down text and handling special tokens, Qwen’s tokenizer ensures structured and coherent responses, making AI-generated conversations more natural.





