
Have you ever wondered how AI models understand text, even when they come across words they’ve never seen before?
This is where tokenization plays a crucial role in Natural Language Processing (NLP).
Tokenization breaks down text into smaller parts, called tokens so that AI models can process them efficiently.
However, a big challenge arises when the model encounters out-of-vocabulary (OOV) words, words that were not included in its training data.
Luckily, Qwen’s tokenizer is designed to handle these OOV words smartly, ensuring that AI can still make sense of new or uncommon words.
In this article, we’ll break down how Qwen’s tokenizer manages unknown words in a simple way.
What Are OOV Words?

Out-of-vocabulary (OOV) words refer to terms that a tokenizer does not recognize because they are not part of its training vocabulary.
This can include new slang, rare words, technical jargon, or even typos.
If a tokenizer cannot process these words properly, it may lead to loss of meaning or broken text analysis.
To prevent this, tokenizers use special techniques to handle OOV words.
How Does Qwen’s Tokenizer Handle OOV Words?

Qwen’s tokenizer ensures smooth text processing by using multiple techniques to handle OOV words efficiently. Let’s explore these techniques in detail.
1. Replacing Unknown Words with a Special Token (unk_token)
When Qwen’s tokenizer encounters an OOV word, it replaces it with a special placeholder known as unk_token (unknown token).
This prevents the model from breaking when processing text that contains unfamiliar words.
Instead of completely discarding the word, the model keeps track of its position in the text and continues processing the sentence.
2. Breaking Words into Smaller Subwords
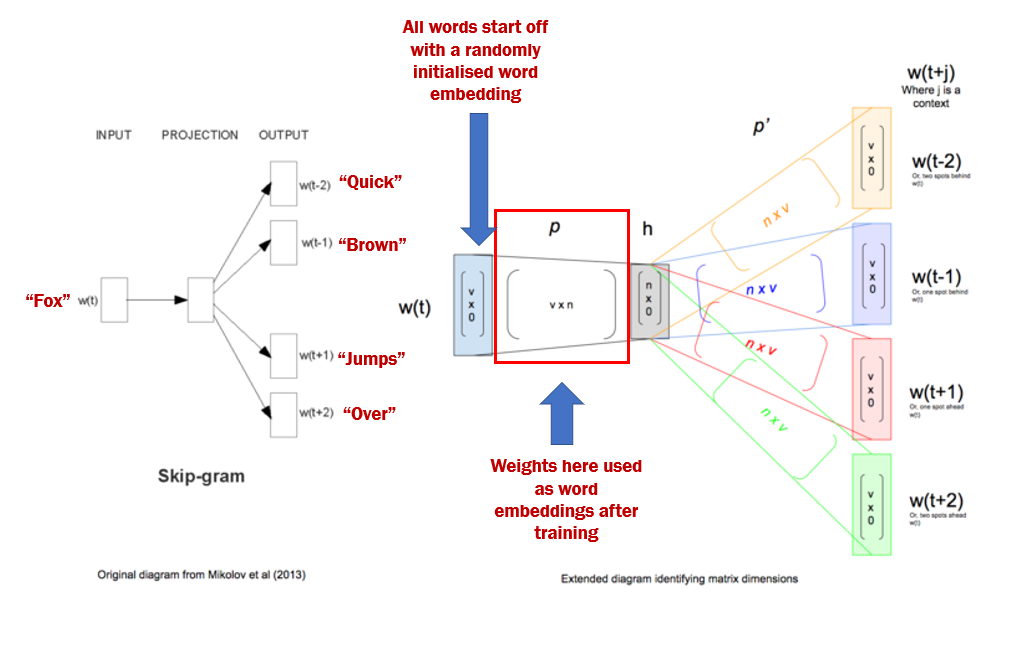
One of the smartest techniques Qwen’s tokenizer uses is subword tokenization.
Instead of treating whole words as a single unit, it breaks them down into smaller, meaningful parts. This allows the model to recognize some aspects of an unknown word.
For example, if the word “autogenerative” is not in the vocabulary, the tokenizer might split it into recognizable subwords like “auto” and “generative” instead of marking the entire word as unknown.
This way, the model still understands part of the word’s meaning.
3. Using Special Tokens for Sentence Structure
To help structure text better, Qwen’s tokenizer includes special tokens:
-
bos_token(Beginning of Sequence Token): Marks the start of a sentence or text input. -
eos_token(End of Sequence Token): Indicates where the sentence or text input ends.
These tokens are useful for applications like text generation and translation, where knowing the start and end of a sentence is essential for accuracy.
Why Is This Important for AI Applications?
Handling OOV words effectively is crucial for various real-world AI applications, such as:
-
Chatbots & AI Assistants: Helps them understand and respond to new or uncommon user inputs.
-
Text Generation: Makes AI-generated content more meaningful and natural.
-
Machine Translation: Allows accurate translation of rare or newly created words.
-
Search Engines: Improves keyword recognition and search results by understanding new terms.
Conclusion

Qwen’s tokenizer is designed to handle unknown words intelligently using special tokens, subword tokenization, and sequence markers.
This ensures that even when the AI model encounters new words, it can still process them efficiently without losing important information.
Understanding how tokenization works is essential for developers and AI enthusiasts, as it helps in building smarter and more adaptable AI-powered applications.
Whether you’re working on chatbots, search engines, or language models, Qwen’s tokenizer ensures your AI can handle the ever-evolving nature of human language.
Frequently Asked Questions (FAQs)
What are out-of-vocabulary (OOV) words?
OOV words are words that a tokenizer does not recognize because they are not in its predefined vocabulary. These can include new slang, technical terms, foreign words, or typos.
Why is handling OOV words important in NLP?
If an NLP model cannot handle OOV words, it may misinterpret text or lose important meaning, reducing the accuracy of applications like chatbots, search engines, and machine translation.
How does Qwen’s tokenizer deal with unknown words?
Qwen’s tokenizer replaces unknown words with a special token (unk_token), breaks words into smaller subwords, and uses special tokens to structure text properly.
What is the unk_token, and how does it work?
The unk_token is a placeholder used when a word is not found in the vocabulary. It helps the model recognize that an unknown word exists in the sentence without breaking the text.
What is subword tokenization, and why is it useful?
Subword tokenization splits words into smaller, recognizable parts. This allows the tokenizer to understand at least some aspects of unknown words instead of marking them as completely unknown.
How does Qwen’s tokenizer handle the start and end of a sequence?
It uses special tokens like bos_token (beginning of sequence) and eos_token (end of sequence) to help structure sentences and improve text generation accuracy.
What are the benefits of Qwen’s tokenizer in AI applications?
Qwen’s tokenizer improves chatbot responses, enhances text generation, ensures better translation accuracy, and boosts search engines by understanding new words more effectively.
Can Qwen’s tokenizer learn new words over time?
No, tokenizers work with a fixed vocabulary. However, by using subword tokenization and handling OOV words properly, models can still process unfamiliar words intelligently.
Is Qwen’s tokenizer better than traditional word-based tokenizers?
Yes, because traditional tokenizers fail when they encounter OOV words, whereas Qwen’s tokenizer intelligently processes them using subword techniques and special tokens.
Where is Qwen’s tokenizer most useful?
Qwen’s tokenizer is widely used in AI-powered applications such as virtual assistants, automated customer support, machine translation, search engines, and text analysis tools.




